微信的联系人
温故知新
本篇我们需要一个 module 叫 reqeusts,这在最初构建虚拟环境时,还尚未安装的。
不论你使用 pipenv 构建的 Python 的虚拟环境,还是直接的 Python 2 环境,还是 brew install python3 构建的 Python 3 环境,现在你需要靠自己安装 requests 这个 module。
requests 是一个经常用到的 module/package,它构建于 urllib、urllib2、urllib3 这些 Python 标准库的基础之上,同时,又很大程度上取代了它们。
很多时候,从产品的角度去考虑,技术服务于用户体验,甚至极端点说,不少前端程序员对于用户体验的把控要优于很多产品经理。但遗憾的是,技术 本身是不怎么考虑用户体验的,不少技术的实现逻辑,非常条理性,甚至条理性到了扼杀用户体验的程度。
当 技术性的产品 有用户体验的时候,它会产生很强的自我发展的能力,产生品牌效应,甚至构建一个新的生态。
抓取微信的好友信息
需要注意但必要性可能不高的警告: 模拟微信的请求,有可能会被微信的安全机制拦截,甚至会影响到自己的账户。换句话说,所有类似的方式,都存在如此潜在的风险。
另外,由于微信自己平台本身的变化,有些请求的逻辑、格式会发生变化,本文涉及到的参考代码未必能在未来一直保持有效,请自己参考整体的思路,思路是不变的。
准备工作
首先,在 https://wx.qq.com/ 登录微信的网页版。有可能你的账户无法登录,或者未来某一天微信停用了 Web 版,那么也没有关系,基本原理的存在,并不依赖于某个 Demo,大概知道怎么回事就可以了。
然后,打开 Chrome 浏览器 的 Inspect(检查) 窗口,找到 Network 的 Tab,勾选 Preserve log,如有必要,可以清除掉已经存在的日志信息。
分析
我们需要相对快速地查看每一个 Network 的请求,会看到一个 URL 中包含 getcontact 以及它最终对应的 Response 是一个 JSON 格式的,并且有 MemberCount 这样的关键字段,那么基本上可以确定,这个 URL 是用以获得当前登录账户的联系人。
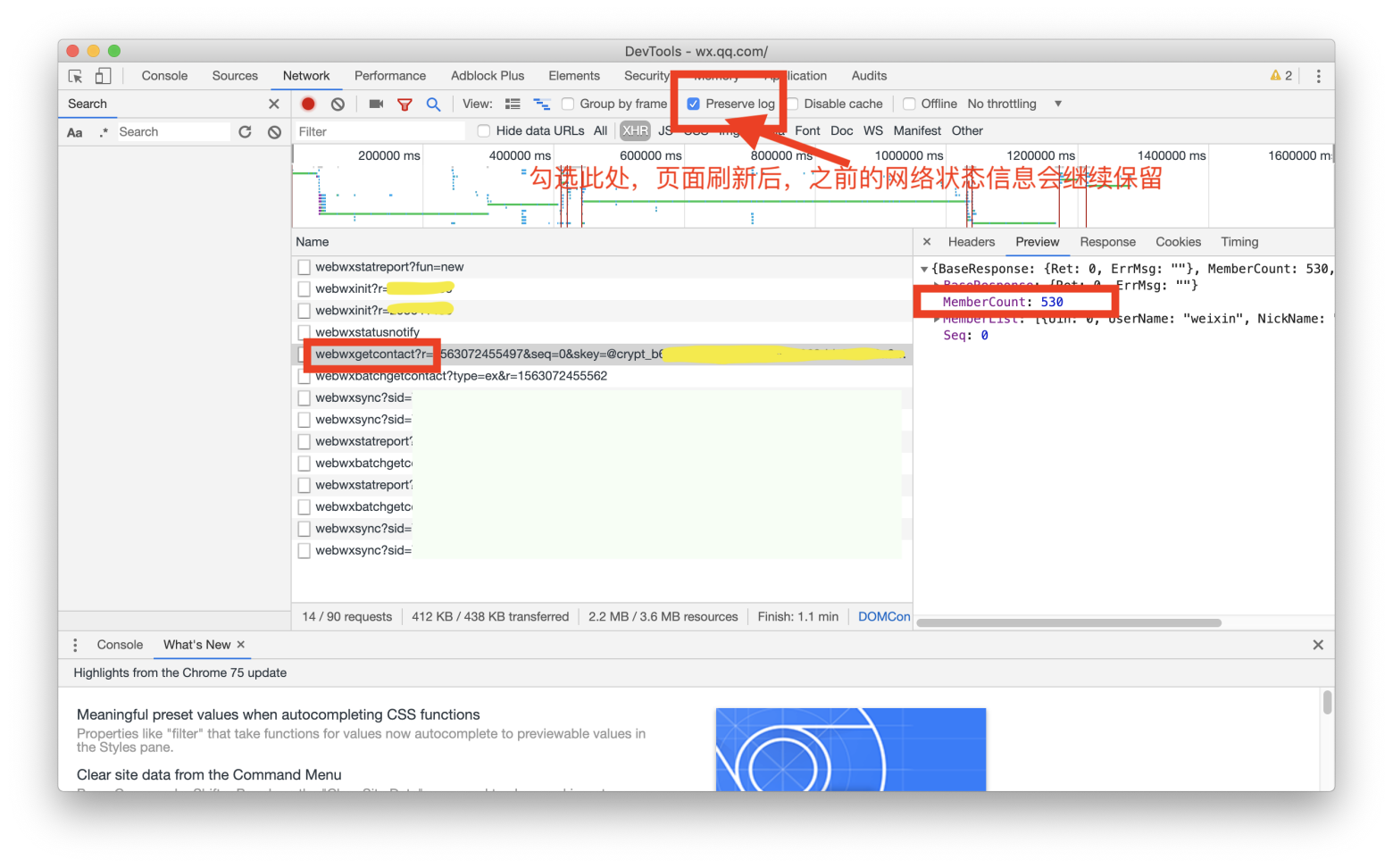
另外,把 Request Headers 的数据全部复制下来 (Host 除外),转为 Python 中的 dict,作为 request.get 的 headers。至于什么是 Request Headers,《FirstWeb》中介绍如何使用 Chrome Debug 里有详细的介绍。
代码
def get_contacts():
url = 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact?r=%s&seq=0&skey=@crypt_换成自己获得的值' % (int(time.time() * 1000))
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '换成自己的 cookie',
'Referer': 'https://wx.qq.com/',
'User-Agent': '换成自己的 user-agent' }
response = requests.get(url, headers=headers)
data = response.json()
for member in data['MemberList']:
info = u'name: {0}\nflag: {1}\nsignature: {2}\n\n'.format(
decode_wechat_string(member.get('NickName', '')),
member.get('ContactFlag', ''),
decode_wechat_string(member.get('Signature', '')), )
print(info)
URL 中有个 r=1563072455562 类似的,基本可以推断出是时间戳,这是平常的经验积累。 由于前端 (Javascript) 产生的时间戳一般会到毫秒,在 Python 中相当于 int(time.time() * 1000)。
headers 则是上段中提到的,可以在 Chrome 浏览器,查看 Network 时候,复制 Request Headers 获得。
一个小小的意外,发现从微信 API 的 URL 上获得的结果,需要额外的编码对应。参考下面的代码 (兼容 Python 2 & Python 3)。
事事总是如此,未必那么顺当,会冒出一些意外。意外的情况,去解决就好了,至于什么原理,其实不用管也可以的。隐约知道是怎么回事,就是编码做了 escape 的处理,至于微信方为什么要这么处理,不知道。对了,escape 这个词怎么翻译,也是比较头疼的,或许不用去翻译就好,以后看多了,你就明白它大概就是这个意思了。
def decode_wechat_string(s):
# for Python 2, bellow line
# s = unicode(s.encode('unicode-escape').decode('string_escape'), 'utf8')
if not s:
return ''
s = codecs.escape_decode(s.encode('unicode-escape'))[0]
try:
s = unicode(s, 'utf8') # python 2
except:
try:
s = str(s, 'utf8') # python 3
except:
pass
return s
运行
if __name__ == '__main__':
get_contacts()
你可以使用 Python 的虚拟环境,直接 python ??.py 或者 python3 ??.py,或者在系统默认的 Python 环境中运行,都是可以的。除了对 requests 这个 module 有依赖之外,整个程序的逻辑还是很简单的,倒不用强调什么虚拟环境了。
大概结果如下图所示:

拓展: 扫码登录是怎么实现的
是不是蛮好奇,微信是怎么实现扫码登录的?
- 网页上一个二维码,存储了某个特定的 ID,然后 Javascript 定时 (比如每隔 3 秒) 去请求某个 URL,查询这个 ID 的状态 (也可以通过 WebSocket);
- 用户在手机 App 端扫二维码,确认登录后,会让第 1 步中 ID 获得可登录的能力;
- 仍然是 第 1 步在不断地重新请求,发现 ID 可以登录了,服务器端给出有了登录权限的 Cookie 或者特定的 Token,登录成功。
定期去查询某个 URL,叫长轮询,还有一个方法,就是使用 WebSocket,它是即时的 (相对长轮询而言)。
简而言之,不要随意扫码,扫一下,有时就把自己的 Token 贡献给对方了,Token 意味着权限。
技术有时也是如此,创造了便捷,也带来安全问题。这个安全问题,未必是技术上的,而是现实生活中的。
一点小小的疏忽 (不小心扫个码),就有暴露自己核心数据的危险。更何况,有那么多人,对此还一窍不通。