写一个 DNS 服务器
一个简单的 DNS 服务器
现在,我们要开始写一个 DNS 服务器了,在开始之前,先明确下这个 DNS 服务器有哪些功能,过于复杂的,还不适合我们现在入门阶段。
这个简单的 DNS 服务器,应该是这样的:
- 只负责解析 A 记录 (IP 地址);
- 指定了某些域名的 A 记录,返回指定的值;
- 非指定域名的 A 记录,则由 8.8.8.8 公共 DNS 服务器解析后,再返回结果 (相当于 Proxy)。
然后,我们开始完成这个 DNS 服务器吧!
一个获取域名 IP 的函数
dns 这个 module 就是之前准备环境中 dnspython 这个库,实际在 Python 中被调用,它却不是 dnspython 这样的名称,也是常见的现象。
from dns.resolver import Resolver
dns_resolver = Resolver()
dns_resolver.nameservers = ["8.8.8.8", "8.8.4.4"]
def get_ip_from_domain(domain):
domain = domain.lower().strip()
try:
return dns_resolver.query(domain, 'A')[0].to_text()
except:
return None
我们使用 try、except 这样一刀切的方式,在极其正规的代码质量来看是不应该的,但是记住,一刀切是个好方法,视场景而定。
使用 try 的逻辑,是因为 domain 对应的 A 记录不存在,会抛出异常,另外还可能网络断网也会有异常。如果解析正常,意味着返回的应该是 IP 格式的文本。但要记住,程序的世界有时要特别小心想当然的事情,在 A 记录获取到之后,还应该判断它是不是合格的 IP 格式,比如获得了 a.b.c.d 或者 999.888.777.1 肯定都不是正确的 IP 地址。
是不是感觉逻辑有些啰嗦,这都要校验吗?代码中经常要处理这些琐碎的校验,不处理,就是潜在的漏洞,即使它可能就是完全画蛇添足,那就画蛇添足吧。
还有个有趣的问题,为什么 get_ip_from_domain 这个函数返回的值可能是两种类型呢?一个是文本类型的 IP,一个则是 None ?
仍然要视场景而定,None 有 None 的意义,文本类型有文本类型的意义,假设 get_ip_from_domain 函数调用后的结果,必然要跟其它字符串一起处理,那么如果找不到 IP,直接返回 '' (空字符) 会更合适。但是,函数调用后,会判断 IP 是否取得了而有不同的 case,则使用 None 更自然。当然,直接把 None 改成 '' 也无碍,看自己喜欢。
要实现一个 Proxy (代理) 的功能,就要用到 DNS 原始的解析逻辑,但不能直接使用 socket.gethostbyname('google.com'),具体的原因,你想一想?我们也可以在命令行中运行 nslookup google.com 8.8.8.8 指定 源 DNS 服务器 查询,虽然 Python 中也能调用命令行命令,但太麻烦了,远不如使用一个 module 来解决更方便。
给出 Response
通过 socket,我们会获得 message 这个变量,解析 后,income_record = DNSRecord.parse(message),获得 income_record 这个变量。相当于 request 过来的字节,转化成了 Python 中的数据对象,这种数据 (格式) 的转化是很常见的,原始的字节对于写代码的我们 (人类) 来说,可不友好。
客户端 (client) 发过来 request,那么我们服务端就要给出 response。
DNS 的解析 reqeust/response,跟 HTTP 的 request/response 也有相似的地方,比如,它们都有 headers (头部信息)。
我们使用的 module 中,不论是 request 还是 response,对应到的对象都来自于 DNSRecord 这个 class,只是 headers 会些不一样,比如 reqeust 的 qr=0, 而 response 的则是 qr=1。至于其它 headers,有兴趣可以去进一步了解,就此作罢,也关系不大。
当解析结果不存在时,我们也要给出 response,并不是想当然 return None 就可以了,不然发 request 过来的 client 后面还会持续发请求过来,这就是无端的浪费性能了。代码参考如下:
from dnslib import DNSRecord, QTYPE, RD, SOA, DNSHeader, RR, A
def reply_for_not_found(income_record):
header = DNSHeader(id=income_record.header.id, bitmap=income_record.header.bitmap, qr=1)
header.set_rcode(0) # 3 DNS_R_NXDOMAIN, 2 DNS_R_SERVFAIL, 0 DNS_R_NOERROR
record = DNSRecord(header, q=income_record.q)
return record
def reply_for_A(income_record, ip, ttl=None):
r_data = A(ip)
header = DNSHeader(id=income_record.header.id, bitmap=income_record.header.bitmap, qr=1)
domain = income_record.q.qname
query_type_int = QTYPE.reverse.get('A') or income_record.q.qtype
record = DNSRecord(header, q=income_record.q, a=RR(domain, query_type_int, rdata=r_data, ttl=ttl))
return record
很多底层代码 (协议) 中,一些类型的表达,是 整数类型,比如 0、1、2,而不会是 type1、type2、type3 这种人类容易容易理解的字符串,比如上面代码中 query_type_int = QTYPE.reverse.get('A') or income_record.q.qtype 就是为了获得 A 记录 这个类型对应的一个 int (整数) 值。
我们构建新的 DNSRecord 时,有一个 ttl 的参数,TTL 的全称是 Time to Live,也就是一个 record 的存活时间。TTL 更多是一个 约定,当 client 得到解析的结果,发现 TTL 是 60 (秒),那么在接下来的 60 秒内,client 就不再去 server 上请求了,也就相当于本地缓存了 60 秒。
我们看到一些 动态DNS 服务商或者更专业的 DNS 服务商,他们都能提供比较低的 TTL 值的支持。不言而喻,低 TTL 值会给 DNS 服务器带来更大的负载,像域名服务商顺道提供的 DNS 服务,TTL 值都是偏高的。
低 TTL 可以让你的解析结果更加灵活,比如服务器挂了,换了一个替代服务器,对应到新的 IP,如果 TTL 很高,那或许要等很久很久新的结果才能生效。但低 TTL 的负面影响,会轻微地降低网站访问速度:网站第一次被访问时,DNS 需要解析,这会耗费时间,但后续基本上不用再解析了,因为 TTL 会产生缓存的效果;如果 TTL 是 1 的时候,相当于每秒都要更新 DNS 缓存,也几乎相当于当前网站每次刷新时,DNS 解析的时间都无法避免了,相当于缓存太短而无意义。
TTL 太高太低,都不好,一般 60~3600 (秒)之间,自己按需选择。这个 TTL 不单纯是我们代码中需要控制的参数,有些时候,也是在 DNS 托管商上设置记录时,需要设定的。
串起整体流程
接下来,我们就将整个流程串起来,DNS 服务器需要 bind 到 53 端口,而且采用 UDP 协议,使用 socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 走的是 UDP 协议。
def dns_handler(s, message, address):
try:
income_record = DNSRecord.parse(message)
except:
logging.error('from %s, parse error' % address)
return
try:
qtype = QTYPE.get(income_record.q.qtype)
except:
qtype = 'unknown'
domain = str(income_record.q.qname).strip('.')
info = '%s -- %s, from %s' % (qtype, domain, address)
if qtype == 'A':
ip = get_ip_from_domain(domain)
if ip:
response = reply_for_A(income_record, ip=ip, ttl=60)
s.sendto(response.pack(), address)
return logging.info(info)
# at last
response = reply_for_not_found(income_record)
s.sendto(response.pack(), address)
logging.info(info)
if __name__ == '__main__':
udp_sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
udp_sock.bind(('', 53))
logging.info('dns server is started')
while True:
message, address = udp_sock.recvfrom(8192)
dns_handler(udp_sock, message, address)
在这个代码运行的逻辑中,用的是 While True 这种永真形式的循环,所以务必要注意,loop 里每次的执行,不能出现错误,一旦出现错误,While True 内部抛出异常,整个程序就挂了。
这个时候,你也可以 def _dns_handler(*args, **kwargs),在里面 try: 运行真正的函数,然后 except: pass,在 While True 的循环中则调用 _dns_hanlder 而不是 dns_hanlder。这也是一种常见的做法。
我们把潜在出错的位置移到其它临时函数中了,而实际场景中,不但要确保不出错,而且有必要还应该再去捕获到出错的原因,以供后续 Debug。
注:return logging.info(info)是loging.info(info)+return None两行合并,因为 loging.info 返回 None。
启动 DNS 服务器
假设刚才的代码文件叫 simple_dns_server.py,如果使用 admin 开启的 PyCharm,你可以直接在 PyCharm 内 Run 或者 Debug simple_dns_server.py。
如果不是 admin 模式开启的 PyCharm,则需要在命令行中运行 sudo python simple_dns_server.py,以 admin 的身份运行这个 Python 程序,才有权限绑定到 53 端口上。
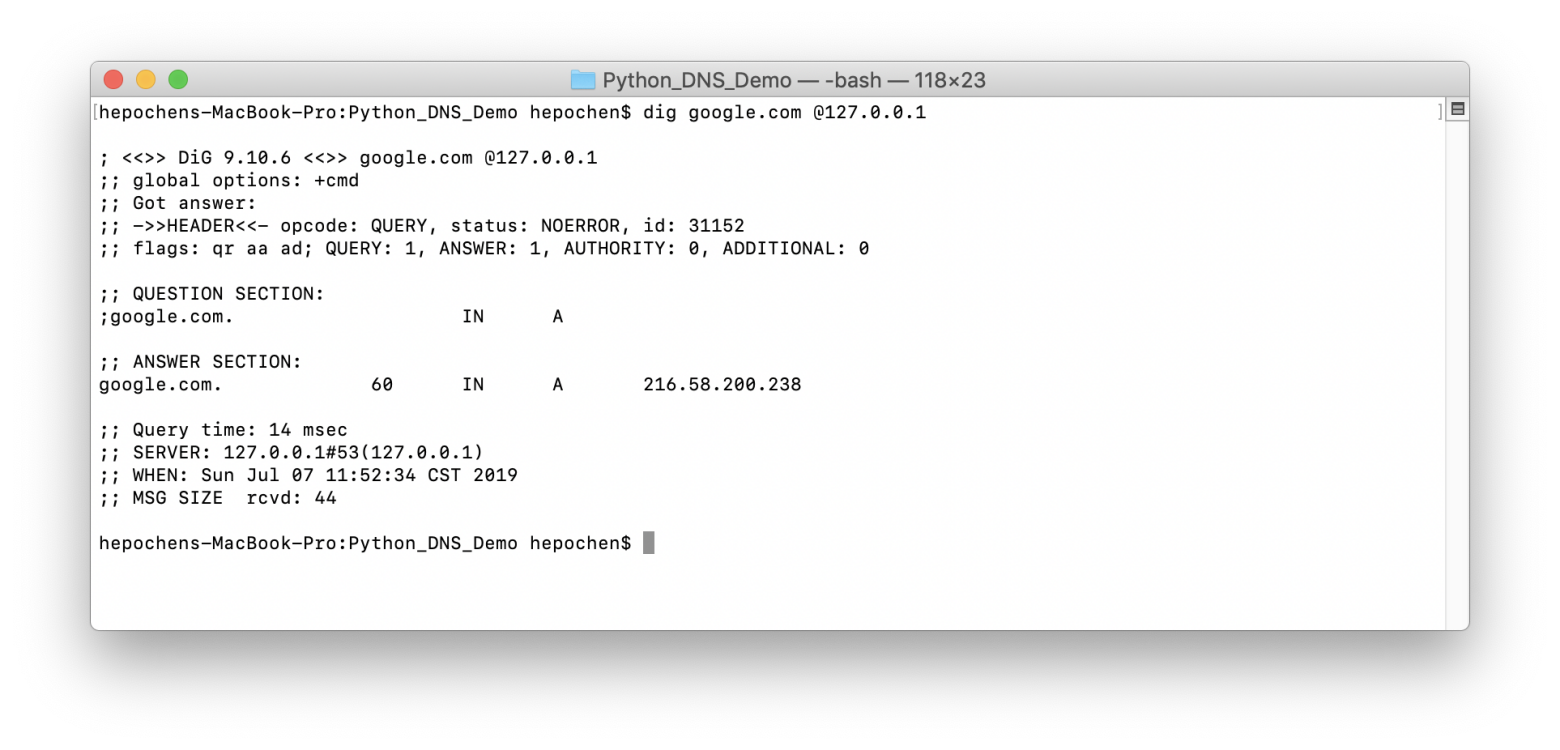
使用 dig 检验效果
我们另开一个命令行窗口,使用 dig 来查询 127.0.0.1 (也就是我们刚刚运行的 DNS 服务器) 上的 DNS 结果,dig google.com @127.0.0.1,结果如下图所示:
一个小任务
是的,我们的 DNS 服务器已经在线了。
但是,我们忘记处理一个 『需求』了,就是指定一些域名返回对应的 IP,比如 baidu.com 可以指向本地 127.0.0.1 试试。至于这部分的代码,自己发挥了:可以在 get_ip_from_domain 这个函数调用之前使用 if、elif 来对应;也可以使用一个 dict 类型来存储所有指定域名对应的 IP;也可以将一个文本文件作为配置文件,但是代码中就需要读取、解析,最终也是转化一个 dict 类型的数据。